Deploying YOLOv8 on
NVIDIA Jetson Orin & Xavier
A production-grade engineering guide for maximizing FPS and minimizing latency using TensorRT and custom CUDA kernels.
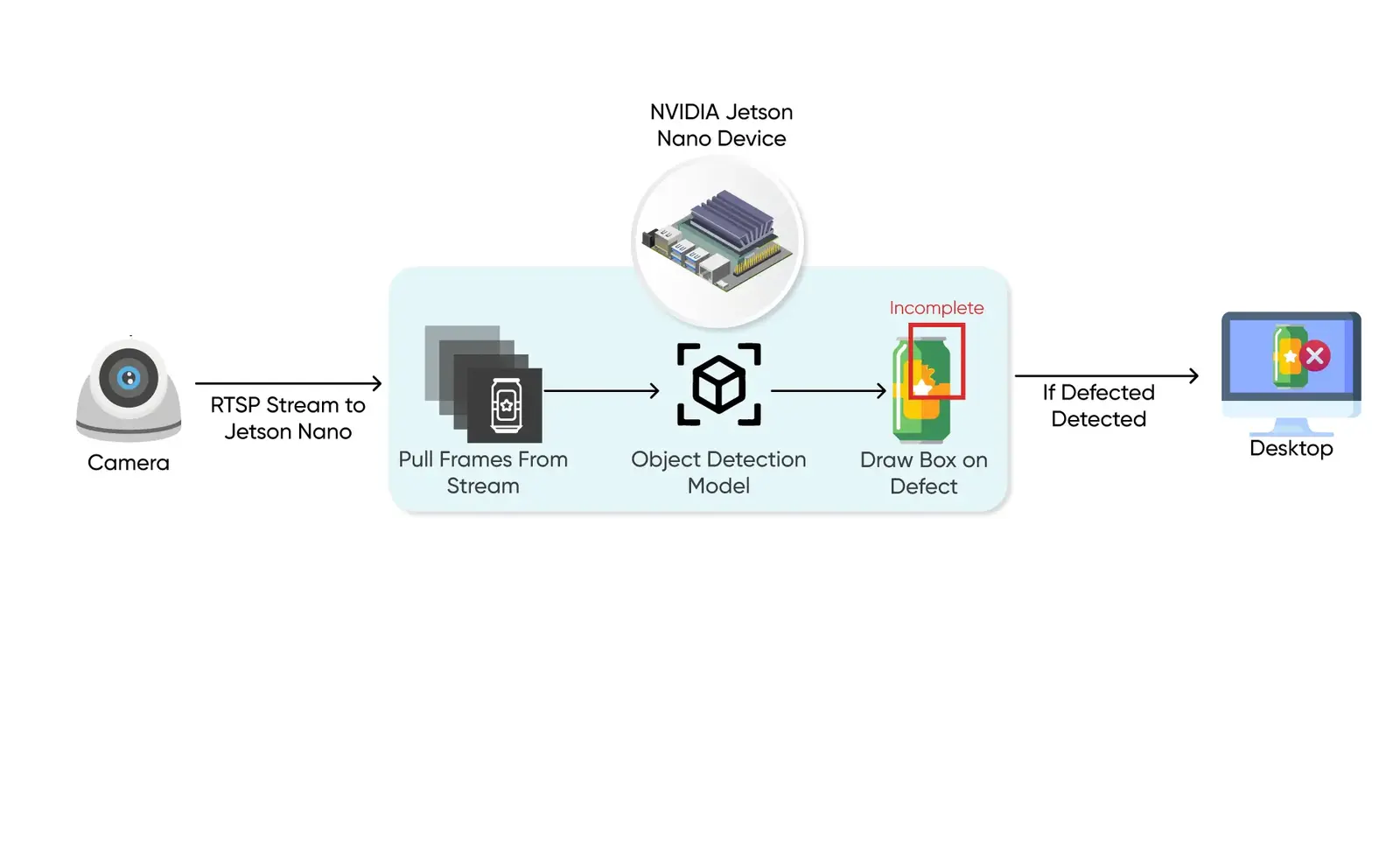
The Pipeline Strategy
For high-stakes computer vision, simple inference is not enough. We must build a **low-latency vertical queue** that manages raw camera streams, TensorRT engines, and downstream logic.
Environment Setup
Proper Jetson deployment begins with a clean environment. We recommend using **JetPack 6.0 (Ubuntu 22.04 core)** to leverage the newest CUDA and cuDNN libraries.
Caution: Ensure your power mode is set to MAXN (Maximum Performance) before running benchmarks.
# Update sources and install core dependencies
sudo apt update && sudo apt upgrade -y
sudo apt install python3-pip libopenblas-base libopenmpi-dev -y
# Verify CUDA visibility
nvcc --versionInstall Ultralytics and TensorRT Support
We use the Ultralytics framework but optimize it for NVIDIA's backend. This allows us to scale from prototyping in PyTorch to production in TensorRT with minimal code changes.
# Install ultralytics
pip3 install ultralytics
# Ensure tensorrt is installed via pip for Python bindings
pip3 install tensorrtModel Export & Quantization
Moving from a `.pt` file to a `.engine` file (TensorRT) is the most critical step for edge performance. On Orin modules, this can reduce latency from 40ms to < 8ms.
We use **FP16 quantization** for the best balance of accuracy and speed. **INT8** is possible for even higher throughput but requires a calibration dataset.
from ultralytics import YOLO
# Load your custom weight
model = YOLO("yolov8n.pt")
# Export to TensorRT format with Half-Precision (FP16)
model.export(format="engine", half=True, device=0)
# The result is 'yolov8n.engine' optimized for YOUR hardwareProduction Inference Script
In a real-world scenario, you want to use the `.engine` directly to avoid PyTorch overhead. Here is a high-performance boilerplate:
import cv2
from ultralytics import YOLO
# Load the compiled TensorRT engine
model = YOLO("yolov8n.engine", task="detect")
# Initialize Gstreamer or RTSP pipeline
cap = cv2.VideoCapture("rtsp://admin:pass@192.168.1.100:554/ch1")
while cap.isOpened():
success, frame = cap.read()
if not success: break
# Run accelerated inference
results = model.predict(frame, stream=True, verbose=False)
# Process results...
for r in results:
# Drawing, logic, and alerting goes here
pass
cap.release()Expert Tip: Multi-Camera Concurrency
Thermal Throttling Prevention
Industrial Jetsons can throttle performance under heavy multi-stream loads. We implement thermal-aware batching that dynamically scales frame-skipping based on chip temperature (accessible via `tegrastats`).
Need Production Edge AI?
We help enterprises build and deploy optimized computer vision models at scale. Let's talk about your deployment goals.
Book a Consultancy